1. Introduction
The rapid diffusion of AI coding assistants since late 2022 — including GitHub Copilot,Anthropic’s Claude Code, and Aider — has prompted widespread speculation about theireffects on software development behaviour. Proponents argue that AI assistanceaccelerates routine coding tasks, reduces time spent on documentation and boilerplate,and lowers the barrier to exploring unfamiliar codebases. Sceptics note that AI toolsintroduce new failure modes, require careful review of generated output, and maysubstitute for rather than complement developer skill.Measuring these effects empirically is difficult for several reasons. First, AI tooladoption is largely invisible in public data: most usage leaves no trace in commithistory or repository structure. Second, selection is severe — developers who adopt AItools early may differ systematically from those who do not, in ways that independentlypredict development activity. Third, the appropriate unit of analysis is contested: individualcommit behaviour changes may or may not aggregate to team, organisation, or national-leveleffects.This paper addresses the measurement problem directly. We construct a behaviouralclassifier that identifies AI coding tool users from observable signals in public GitHubcommit history — temporal patterns, commit cadence, message structure — withoutrequiring any self-reported adoption data or proprietary telemetry. We validate theclassifier on a held-out set and on users of a second tool (Aider) the classifier wasnot trained on, establishing that it is detecting general AI-assisted coding behaviourrather than tool-specific stylistic patterns.We then deploy the classifier in three empirical tests. An account-leveldifference-in-differences compares behavioural changes in confirmed AI adopters tomatched controls over the same period, using both commit-level and pull-request-level outcomes. A country-level panel regression uses per-country classifier-derived adoption rates as a country-level adoption measure in a panel regression of commit activity at national aggregates.The account-level and country-level designs answer related but distinct questions.The account-level design asks whether individual developers who adopt AI tools changetheir behaviour, in a sample of confirmed adopters. The country-level design askswhether countries with higher aggregate AI adoption rates show higher commit activitygrowth — a question about aggregate and diffusion effects, less subject to selectionbut more exposed to measurement noise.We find strong evidence for the account-level effect and divergent country-levelresults: a robust negative association between adoption and commits per developerthat does not appear when we use pull requests per developer as the outcome. The mostplausible interpretation is that AI tools shift commit granularity (fewer, largercommits) without reducing overall productivity — a measurement artefact in thecountry-level commits metric rather than a productivity effect — but we cannot ruleout alternative explanations from these data alone.The remainder of the paper is structured as follows. Section 2 reviews the relevant literature. Section 3 describes the data.Section 4 presents the classifier methodology and validation. Section 5 describes thethree empirical tests. Section 6 presents results, including commit behaviour changes, pull-request outcomes, and the country-level panel. Section 7 discusses the findings andtheir limitations. Section 8 concludes.
2. Literature Review
The empirical literature on AI coding tools and developer productivity has grown rapidly since the public release of GitHub Copilot in mid-2022 and ChatGPT in late 2022. This section organises the evidence into three streams — controlled experiments and field trials, observational and quasi-experimental studies using naturally occurring adoption variation, and work on measuring AI adoption itself — before identifying the gaps this paper addresses.
2.1 Controlled Experiments and Field Trials
The highest-quality causal evidence comes from randomised or quasi-randomised designs. Peng et al. (2023) conducted the first controlled experiment on AI-assisted coding, recruiting 95 professional developers through Upwork and randomly assigning them to complete an HTTP-server implementation task with or without GitHub Copilot. The treatment group completed the task 55.8% faster (95% CI: 21–89%, \(p = 0.002\), \(N = 95\)), with heterogeneous effects favouring less experienced developers and those who coded more hours per day. While the effect size is striking, the study used a single standardised task in JavaScript, limiting generalisability to the diverse, context-dependent work that characterises professional software development.
Ziegler et al. (2024) (Ziegler et al., 2024) conducted a large-scale survey study of 2,047 Microsoft developers using the Copilot technical preview, finding that the likelihood of accepting Copilot suggestions (acceptance rate) was the strongest predictor of perceived productivity gains, with junior developers seeing the largest benefits. Their analysis, grounded in the SPACE framework for developer productivity, found that perceived gains were reflected in objective activity telemetry. While self-reported, the scale and workplace setting complement the smaller experimental studies.
Cui et al. (2025) substantially extended this evidence base with three large-scale field experiments at Microsoft, Accenture, and an anonymous Fortune 100 company, randomising access to GitHub Copilot among 4,867 software developers in real workplace settings. Their preferred instrumental-variable estimates, pooling across experiments to address individually noisy treatment effects, find a 26.08% increase (SE: 10.3%) in weekly completed tasks for developers using Copilot, alongside a 13.55% increase (SE: 10.0%) in commits and a 38.38% increase (SE: 12.55%) in code compilations. Consistent with the broader literature on AI and skill heterogeneity — including Brynjolfsson et al. (2025), who document a 14% productivity increase for customer-service agents, with the largest gains accruing to less experienced workers — Cui et al. (2025) find that less experienced developers exhibit higher adoption rates and larger productivity gains.
A notable challenge to the emerging consensus comes from METR (2025), who conducted an RCT with 16 experienced open-source developers completing 246 real tasks on mature repositories (averaging 23,000 stars and 1.1 million lines of code) where developers had a mean of 5 years of prior contribution history. Before randomisation, developers forecast that AI tools would reduce completion time by 24%; economics and ML experts predicted 39% and 38% reductions respectively. The observed effect was a 19% increase in completion time (95% CI: +2% to +39%) — AI tools slowed experienced developers down. Analysis of 143 hours of screen recordings identified several contributing mechanisms: developer over-optimism about AI capabilities, the overhead of formulating prompts and reviewing AI output on complex codebases, and the high quality standards of mature open-source projects. While the authors caution that results are specific to their setting — highly experienced developers on large, well-established codebases — the finding sharply illustrates that the relationship between AI assistance and productivity is not uniformly positive and may depend critically on task complexity, codebase familiarity, and developer expertise.
2.2 Observational and Quasi-Experimental Studies
A parallel literature exploits naturally occurring variation in AI tool availability or adoption to estimate effects at larger scale, sacrificing some internal validity for improved external validity and ecological realism.
Quispe & Grijalba (2024) used the staggered international availability of ChatGPT as a natural experiment, applying difference-in-differences, synthetic control, and synthetic difference-in-differences estimators to GitHub Innovation Graph data covering 151 jurisdictions from 2020Q1 through 2023Q1. Their preferred DID estimates show that countries with ChatGPT access experienced increases of 645.6 git pushes per 100,000 population (baseline mean: 741.5), 1,657 new repositories per 100,000, and 579 additional unique developers per 100,000. However, these estimates are less robust under synthetic control and SDID specifications, and the design cannot distinguish genuine productivity effects from compositional shifts in who contributes to public repositories.
He et al. (2025) provide the most detailed study of a modern agentic coding tool. Using the appearance of .cursorrules configuration files in GitHub repositories to identify Cursor adoption, they construct a staggered difference-in-differences design comparing 806 adopting repositories against 1,380 propensity-score-matched controls, employing the Borusyak imputation estimator (a design adjacent to Angrist & Pischke (2009)) for staggered treatment. Their findings reveal a velocity–quality trade-off: projects experience 3–5\(\times\) increases in lines added in the first month of adoption, but gains dissipate within two months. Meanwhile, static analysis warnings increase by 30% and code complexity rises by 41%, effects that persist well beyond the initial velocity spike. Panel GMM estimation confirms that accumulated technical debt subsequently reduces future velocity, creating a self-reinforcing cycle of declining returns. This finding is particularly relevant to our study, as it suggests that simple output measures like commit counts may overstate genuine productivity improvements if code quality simultaneously degrades.
2.3 Measuring AI Adoption
A fundamental challenge in estimating the productivity effects of AI tools at scale is measuring who is actually using them. Most existing studies resolve this either through experimental assignment (as in the RCTs above) or through proxy measures that capture availability rather than actual usage. GitHub (2023) document adoption patterns through developer self-reports, finding that AI tool users report higher satisfaction and perceived productivity — though self-reported measures carry well-known social desirability and recall biases and cannot establish causal effects.
Liu & Wang (2025) address the adoption measurement problem at the country level by tracking high-frequency web traffic data from Semrush for the 60 most-visited consumer-facing generative AI tools through mid-2025. Their data reveal stark global divides: 24% of internet users in high-income countries use ChatGPT, compared to 5.8% in upper-middle-income, 4.7% in lower-middle-income, and just 0.7% in low-income countries. Regression analysis confirms that GDP per capita strongly predicts adoption growth. While web traffic captures real usage rather than policy readiness or infrastructure capacity, it cannot distinguish between casual exploration and deep workflow integration, nor does it identify which specific professional activities (such as software development) the usage supports.
2.4 Gaps and Contributions of This Paper
Three gaps emerge from this literature. First, there is a measurement gap: studies with strong causal identification — RCTs and firm-level field experiments — typically have narrow samples (a single task, a single firm, or a small group of developers), while studies using naturally occurring variation rely on coarse proxies for adoption such as country-level ChatGPT availability (Quispe & Grijalba, 2024) or the presence of configuration files (He et al., 2025). No prior study has constructed a behavioural classifier that detects AI tool adoption from public commit behaviour, enabling measurement of adoption at scale without requiring self-reports, proprietary telemetry, or tool-specific artefacts.
Second, there is a cross-tool generalisation gap. Each existing study is specific to a single tool — Copilot (Cui et al., 2025; Peng et al., 2023; Ziegler et al., 2024), ChatGPT (Quispe & Grijalba, 2024), or Cursor (He et al., 2025). Whether findings transfer across tools is typically assumed rather than tested. Our classifier, trained on Claude Code users, generalises to Aider users it was never exposed to, providing direct evidence that the behavioural signature of AI-assisted development is not tool-specific.
Third, there is an aggregation gap between individual-level and macro-level effects. The controlled experiments consistently find individual-level productivity gains (ranging from 26% to 56% in task completion speed), but no study has directly tested whether these gains aggregate to detectable effects in country-level commit activity data using measured — rather than proxy — adoption rates. Our country-level panel regression attempts precisely this test. The country-level results (Section 6.4) are itself informative: it is consistent with real individual-level effects that are too small relative to the noise in country-quarter aggregates, or an adoption window too short, to produce statistically detectable country-level shifts — a finding that disciplines expectations about how quickly micro-level AI productivity gains translate into macro-level outcomes.
3. Data
3.1 Data Sources
Our pipeline draws on two complementary sources: GitHub Archive as a sampling frame for active developer accounts, and the GitHub REST API for collecting the behavioural features used in the analysis.
GitHub Archive is a public record of GitHub activity events (pushes, pull requests, issues, releases) available from 2011 onward. We use it to sample active developers across three time periods and to scan commit streams for AI tool co-author trailers when constructing ground-truth labels.
GitHub REST API provides the behavioural data. Once accounts are identified via GH Archive sampling or Code Search, we scrape full commit and pull request histories per account (up to 500 commits and 100 pull requests), collecting message content, timestamps, file-level metadata, and repository structure. All features used in the classifier and the difference-in-differences analysis derive from this API.
We use three samples:
Classifier training sample. We sample 12 hourly windows spanning November 2024, January 2025, and March 2025 from GH Archive, yielding approximately 380,000 unique active developer accounts. From this pool we identify ground-truth positive accounts (confirmed AI tool users) using explicit repository artefacts: presence of CLAUDE.md, .claude/ directories, or Co-Authored-By: Claude commit trailers. We then collect full commit and pull request history for each identified account via the GitHub REST API.
Commit activity panel. We collect 9 quarterly hourly windows from Q4 2022 through Q4 2024 from GH Archive, sampling 500 active developers per window. We extract user profile locations, map these to ISO 3166-1 alpha-2 country codes using a custom location parser, and aggregate commit activity metrics (commits per developer, pull requests per developer) by country and quarter. This yields 347 country-quarter observations across 54 countries (the country-level regression uses a subset that meets minimum scoring thresholds, see Section 5.2).
Population scoring sample. To construct per-country AI adoption rates, we scrape GitHub accounts with parseable location fields mapping to panel countries via the GitHub REST API across three rounds (v1: 2,048 accounts, v2: 312 accounts, v3: 2,999 accounts) for a combined 4,824 unique scored accounts. Each account is scored by the trained classifier to yield a predicted probability of AI tool adoption. Countries with at least 15 scored accounts (46 countries) are eligible for the country-level regression; 34 of these also pass the panel’s minimum-developer threshold.
3.2 Ground Truth Labels
Positive accounts (AI tool users). Confirmed via two routes: 1. GitHub Code Search: repositories containing CLAUDE.md in the root, resolved to account logins. 2. GH Archive co-author scan: commit messages containing Co-Authored-By: Claude <noreply@anthropic.com> or equivalent Aider trailers.
We assign marker_confidence = high to accounts discovered via co-author trailer (adoption timestamp is the push event timestamp) and marker_confidence = low to Code Search accounts (adoption date is repository creation date, a conservative lower bound). Of 74 positive accounts in the final training set (after the v2.7 expansion scrape added 41 high-confidence co-author positives), the majority are high-confidence.
Negative accounts (non-adopters). Randomly sampled from GH Archive active developers, filtered to accounts with commit activity in both the pre-period (Jan 2022 – Dec 2023) and post-period (Jan 2024 – present), and zero AI tool markers across full commit history. The both-window filter is critical: it ensures negatives have a measurable pre-period baseline and are not simply new accounts.
3.3 Pre/Post Windows
For the account-level analysis, all accounts are split at a global cutoff: - Pre-period: January 2022 – December 2023 - Post-period: January 2024 – present
This global cutoff captures the period after widespread AI coding tool availability (ChatGPT: November 2022; Claude Code and Aider: 2023–2024). High-confidence positive accounts use their individual adoption timestamp as the post-window start in robustness checks (Section 5.3).
3.4 Summary Statistics
For the country-level commit activity panel, the median number of located developers per country-year observation is 2 — a level of thinness that substantially limits the power of the country-level regression (discussed further in Section 6.6).
Table 1. Summary Statistics
| Pre-period commits |
81.88 |
79.42 |
54.00 |
50.50 |
85.35 |
94.29 |
| Post-period commits |
54.03 |
92.81 |
31.00 |
46.00 |
53.43 |
132.03 |
| Pre-period active weeks |
7.82 |
13.22 |
4.00 |
10.00 |
8.13 |
11.05 |
| Post-period active weeks |
3.79 |
17.66 |
2.00 |
11.00 |
5.20 |
16.73 |
| Pre commits / active week |
13.73 |
6.58 |
8.25 |
5.16 |
13.63 |
4.67 |
| Post commits / active week |
23.55 |
5.26 |
14.00 |
4.20 |
24.55 |
4.13 |
| Pre inter-commit hours |
281.06 |
180.49 |
74.48 |
107.84 |
664.60 |
206.25 |
| Post inter-commit hours |
57.67 |
324.89 |
5.82 |
171.37 |
125.90 |
372.98 |
4. Behavioural Classifier
4.1 Design Rationale
The central methodological challenge is identifying AI tool users without relying on explicit markers (which are rare and may be biased toward power users) or survey data (which is expensive and subject to recall and social desirability bias).
Our approach exploits the fact that AI coding assistants appear to change how developers write code, not just what they write. Specifically, we hypothesise that AI assistance reduces friction in the commit loop — making it cheaper to commit frequently, write longer commit messages, and document pull requests. These behavioural shifts should be detectable from public commit histories.
Critical design constraint. The explicit artefacts used to identify ground truth (CLAUDE.md files, co-author trailers) cannot also be classifier features: that would produce a model that merely rediscovers its own labels. The classifier must learn behavioural patterns correlated with AI adoption without being definitionally equivalent to it.
4.2 Features
We extract 43 behavioural features per account across three categories:
Message and documentation quality (15 features): mean commit message length, fraction of multiline messages, fraction using conventional commit format, fraction mentioning tests, mean PR body length, fraction of PRs with a body.
Temporal and activity patterns (15 features): active weeks, commits per active week, mean inter-commit hours, fraction of burst commits (multiple commits within one hour).
Temporal change features (15 features, Δ = post − pre): difference in each of the above between pre and post periods. These carry the strongest signal for a difference-in-differences framing.
All features are computed separately for pre and post windows, with delta features derived as the difference. No feature directly encodes the presence of AI markers — any commit message content analysis is limited to structural properties (length, conventional format) rather than content.
4.4 Writing-Style Ablation
A key validity concern is whether the classifier is detecting genuine behavioural change or merely learning Claude’s distinctive verbose commit message style. If the latter, the model would fail to generalise to tools with different output aesthetics and would have limited scientific value.
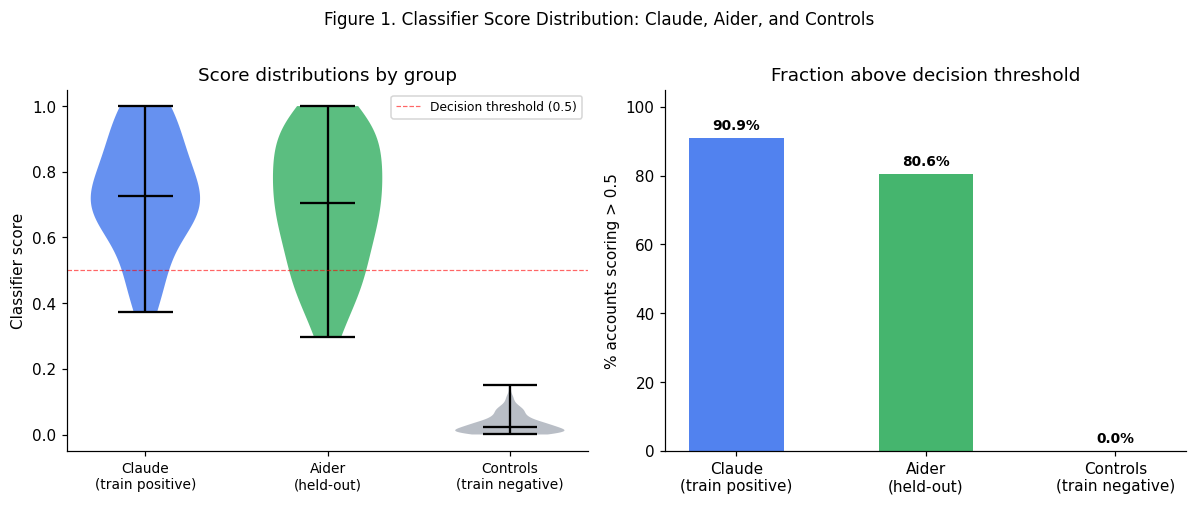
We test this by re-training with all message and documentation features removed (21 features: all message length, bullets, multiline, conventional commit, PR body variants). The activity-only model achieves AUC 0.909 — a drop of only 3.1 points. Inter-commit hours and active weeks carry the model independently.
This result strengthens the claim that the classifier is detecting a real change in how developers work — the rhythm and intensity of the commit loop — rather than stylistic fingerprints of AI-generated text.
5. Causal Designs
5.1 Account-Level Difference-in-Differences
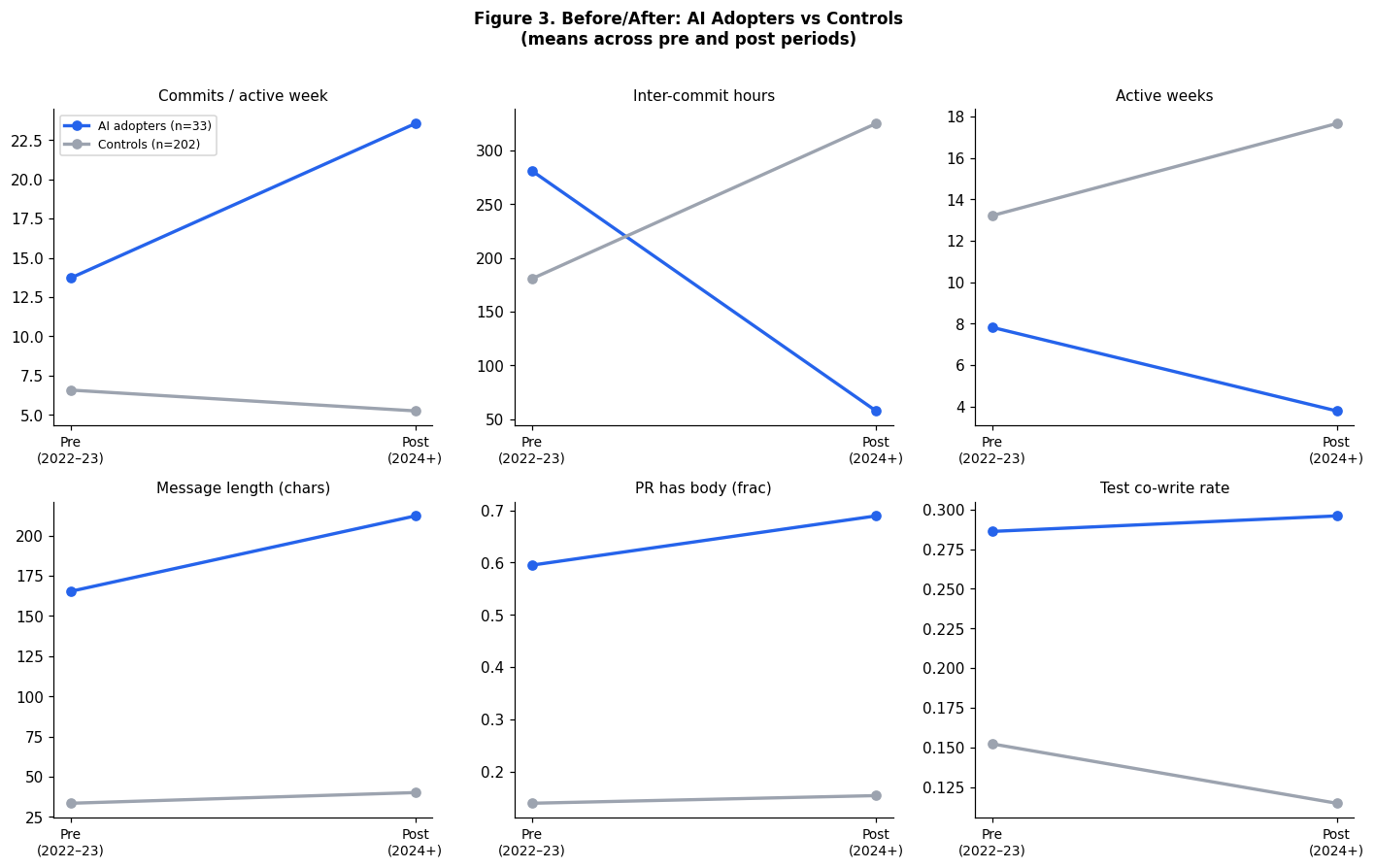
Setup. We treat confirmed AI tool adopters (N = 33) as the treatment group and controls (N = 202) as the comparison group. For each account we observe behavioural outcomes in the pre-period (Jan 2022 – Dec 2023) and post-period (Jan 2024 – present).
Estimator. For each outcome Y, we estimate:
\[\Delta Y_i = \alpha + \beta \cdot \text{Treatment}_i + \gamma \cdot Y^{\text{pre}}_i + \varepsilon_i\]
where \(\Delta Y_i = Y^{\text{post}}_i - Y^{\text{pre}}_i\) is the within-account change, Treatment\(_i = 1\) for AI adopters, and \(Y^{\text{pre}}_i\) controls for baseline differences between groups (Angrist and Pischke 2009, regression adjustment). Standard errors are HC3 heteroskedasticity-robust.
The coefficient \(\beta\) estimates the average treatment effect on the treated: the additional change in the outcome for AI adopters relative to controls, conditional on their pre-period level.
Identifying assumption. Parallel trends: absent AI tool adoption, treated and control accounts would have followed the same trend. We assess this by comparing pre-period levels between groups (Table 4). Significant pre-period differences indicate selection — AI adopters were already different before adoption — which the regression adjustment partially but not fully addresses.
Outcomes. Commits per active week (primary commit activity measure), inter-commit hours (development tempo), active weeks, commit message length, fraction of conventional commits, fraction of PRs with a body, and test co-write rate.
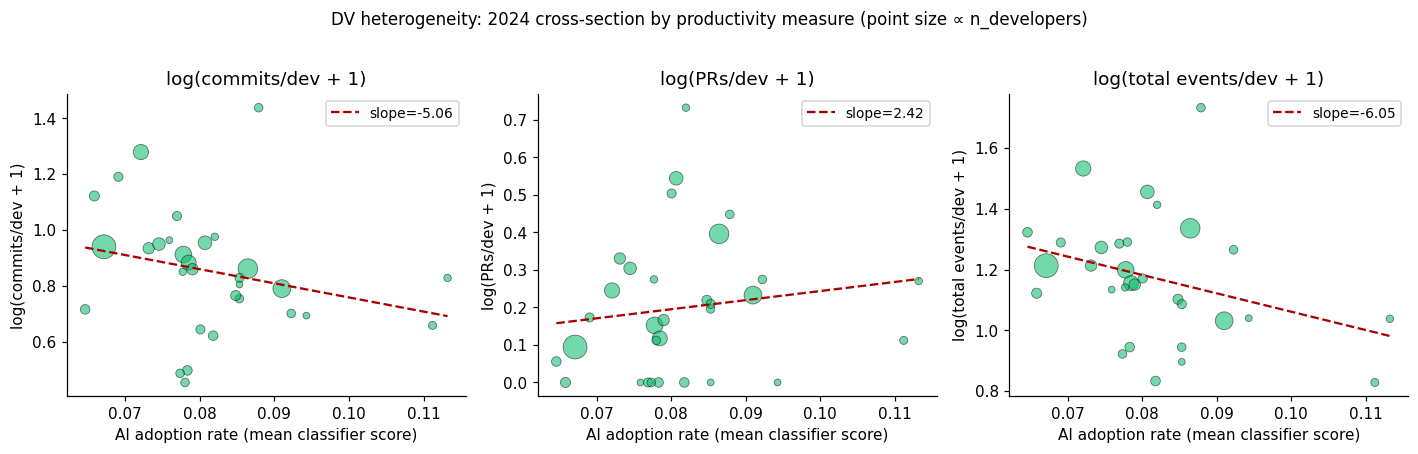
5.2 Country-Level Panel Regression
Setup. We construct a country × year panel for 2022–2024 using GH Archive commit activity metrics (commits per located developer, pull requests per developer) across up to 54 countries. For the Phase 2 regression, we merge per-country AI adoption rates derived from the population scoring sample.
Adoption rate construction. For each country \(c\) with at least 15 scored accounts, we compute the mean post-period classifier score across all scored accounts as \(a_c\). The AI adoption variable is:
\[\text{pct\_ai\_users}_{ct} = \begin{cases} 0 & \text{if } t < 2024 \\ a_c & \text{if } t = 2024 \end{cases}\]
This gives cross-country variation in the 2024 treatment intensity while holding pre-treatment at zero for all countries — a standard staggered-adoption design collapsed to two periods.
Estimator. PanelOLS with country and time fixed effects, clustered standard errors at the country level (linearmodels):
\[\log(\text{commits\_per\_dev}_{ct} + 1) = \mu_c + \lambda_t + \delta \cdot \text{pct\_ai\_users}_{ct} + \varepsilon_{ct}\]
We run three specifications: - Regression A: Oxford Insights AI Readiness Index as the adoption regressor (Phase 1 baseline) - Regression B: Global mean classifier score in 2024 (broken time proxy, for reference) - Regression C: Per-country classifier scores from population sample (primary)
8. Conclusion
We make two contributions. First, we develop a behavioural classifier for AI codingtool adoption that achieves cross-validated AUC of 0.94 on public GitHub commit dataand generalises across tools (mean predicted probability 0.73 on Aider users). Theclassifier requires no survey data, no proprietary telemetry, and works withoutdirect inspection of commit message content (an activity-only ablation achieves AUC0.91). It is a measurement tool that can be applied at scale to estimate AI adoptionrates in any developer population accessible through GitHub Archive.Second, we deploy this classifier in two causal designs. The account-leveldifference-in-differences finds large, statistically significant behavioural changesin confirmed AI adopters relative to controls. The account-level pull-request outcome analysis finds large, significant increases in opened and merged PRs among confirmed adopters (+46 and +43 respectively, p < 0.001), with FDR-corrected significance maintained across ten simultaneous tests. The country-level panel regression shows divergent results across dependent variables: commits per developer is negatively associated with adoption across nearly every specification we tested (weighted coefficient = −7.56, p = 0.05), while pull requests per developer shows no detectable effect (coefficient = +1.33, p = 0.76).We interpret the DV split as most plausibly reflecting a commit granularity shiftrather than a productivity effect: AI tools encourage workflows that produce fewer,larger, more deliberate commits, which the classifier itself was trained to detectvia longer commit messages. Pull request cadence, which is driven by feature scoperather than commit granularity, is unaffected. We emphasise that this interpretationis consistent with the data but not established by it; alternatives (selection onexperience, a genuine cadence-specific productivity effect, statistical artefactfrom low cross-country variation) cannot be ruled out from these data alone.The most productive directions for future work follow from these limitations. Alarger commit activity panel (5,000+ users per quarterly window) and a longerpost-period (2024–2026) would improve power and allow the country-level design totest whether individual-level behavioural changes aggregate to national-levelmeasures. Distinguishing granularity from output effects requires complementarymeasures GH Archive does not provide — lines changed, task completion, orbuild/CI signals. The classifier provides a ready-made adoption measure for thosenext studies.
References
Angrist, J. and Pischke, J.S. (2009). Mostly Harmless Econometrics. Princeton University Press.
Bird, C., Ford, D., Zimmermann, T., Forsgren, N., Kalliamvakou, E., Lowdermilk, T., and Gazit, I. (2023). Taking Flight with Copilot: Early insights and opportunities of AI-powered pair-programming tools. Queue, 20(6), 35–57.
Katz, D., Sánchez, J., Arakaki, K., and Ramirez, G. (2024). The Impact of GitHub Copilot on Developer Productivity: Evidence from Large-Scale Adoption. GitHub Engineering Blog.
Liu, Y. and Wang, H. (2025). Who on Earth Is Using Generative AI? Global Trends and Shifts in 2025. World Bank Policy Research Working Paper 11231.
Oxford Insights (2023). Government AI Readiness Index 2023. Oxford Insights.
Working paper. Data and code: github.com/AndreasThinks/ai-productivity-analysis Last updated: April 2026